AudiopaLM是谷歌新的大型语言模型可以说和听
人工智能世界日新月异地不断发展。尽管有人认为人工智能会削减许多人的工资,使他们失业,但人工智能已经证明,在学校或大学作业方面,甚至通过对无数研究页面的分析,人工智能本身是一个巨大的帮助。在这一点上,谷歌带来了最新的开发成果,称为 AudiopaLM。这种新的语言模型具有高精度的听、说和翻译能力。
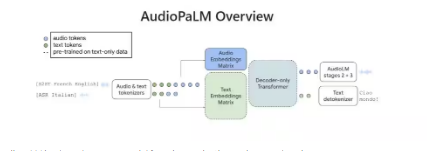
AudiopaLM 是一个用于语音生成和理解的大型语言模型。基于文本和基于语音的语言模型(PaLM-2、AudioLM 和 AudioPaLM)分别组合成一个多模式架构,可以处理和生成文本和语音,用于语音识别和语音到语音翻译应用。仅在 PaLM-2 和 AudioLM 等大型语言模型中找到的语言信息将被传递到 AudioPaLM,并具有保留说话者识别和语气等副语言信息的能力。
通过 AudioPaLM,Google 展示了通过使用纯文本大型语言模型的权重初始化 AudioPaLM 来改进语音处理,成功地利用预训练中使用的大量文本训练数据来帮助完成语音任务。由此产生的模型比最先进的系统执行语音翻译任务要好得多,并且它可以对训练期间未遇到输入或目标语言组合的多种语言执行零样本语音到文本翻译。此外,AudioPaLM 还展示了音频语言模型如何通过在语言之间传输语音来响应简短的口头提示来工作。
语音到语音翻译和自动语音识别是 AudioPaLM 模型的示例。为了对新的音频标记集合进行建模,该平台增加了预训练的纯文本模型(虚线)的嵌入矩阵。模型架构在其他方面保持不变;它从由文本和音频标记的混合序列组成的输入中解码文本或音频标记。随后的 AudioLM 阶段将音频令牌传输回原始音频。
此前,谷歌推出了AudioLM。它是一个用于长时间生成高质量音频的框架。在这个表示空间中,AudioLM 通过将输入音频映射到一系列离散标记,将音频生成构建为语言建模任务。该平台展示了当前可用的音频分词器在重建质量和长期结构之间进行的许多权衡,并且该平台建议采用混合分词策略来实现这两个目标。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
作为全部11支MotoGP车队及90% Moto2和Moto3车队的供应商,布雷博如今已成为顶级摩托车赛事的技术标杆。全球制...浏览全文>>
-
(2025 年 6 月 14 日,广州)6 月 14 日晚,华语摇滚乐坛标志性人物苏见信(信)携「尽兴而活」巡回...浏览全文>>
-
(2025 年 6 月 14 日,广州)6 月 14 日晚,华语摇滚乐坛标志性人物苏见信(信)携「尽兴而活」巡回...浏览全文>>
-
淮北威然是一款备受关注的商务MPV车型,以其宽敞的空间、豪华的内饰和卓越的舒适性吸引了众多消费者的目光。对...浏览全文>>
-
途观X作为上汽大众旗下的高端轿跑SUV,凭借其独特的设计和强劲的性能吸引了众多消费者的关注。在淮南地区,途...浏览全文>>
-
探岳X作为一款备受关注的中型SUV,凭借其时尚的设计和出色的性能,在市场上一直拥有不错的口碑。对于有意购买...浏览全文>>
-
2025款大众高尔夫GTI作为一款备受关注的高性能紧凑型轿车,在汽车市场中一直占据着重要地位。对于安徽亳州地区...浏览全文>>
-
池州长安启源C798作为一款备受关注的新能源车型,在市场上一直保持着较高的热度。随着消费者对新能源汽车需求...浏览全文>>
-
安徽池州地区的汽车市场近期迎来了一波喜讯,2025款高尔夫GTI的新车报价再次刷新了消费者的期待。这款备受瞩目...浏览全文>>
-
济南揽境作为一款备受关注的中大型SUV,其2025新款在外观设计、内饰配置以及动力性能方面均进行了全面升级。新...浏览全文>>
- 三星获得基于一天中的时间和天气的人工智能壁纸功能专利
- 如何将陶瓷融入室内设计
- 努萨海滨豪宅标价 2000 万美元
- 三星 Galaxy S25 Slim:泄露 iPhone 17 Air 竞争对手的旗舰相机规格
- AMD Radeon RX 8800 XT 参考设计在意外广告中泄露
- M3 Touring 与 RS4 Avant:终极冬季测试
- 量产版 Corvette 仅用了令人震惊的 2.3 秒就从 0 加速到 60 英里/小时
- 婴儿潮一代希望房价上涨
- 购买 OnePlus 12 可节省 250 美元
- 更新后的奥迪 E-tron GT:性能和价格均有所提高
- 达尔文市场将在 2025 年回暖
- Circle to Search 可能看起来更像 Apple Intelligence
- 2023年财富全球论坛荣耀对可折叠智能手机等的预测
- TECNO Spark Go 2024配备6.6英寸90Hz显示屏立体声扬声器在发布前预告
- 橡树城改造扩大到包括豪华生活的定制住宅
- Netflix将哈迪斯时空幻境和死亡之门添加到其游戏库中
- 联想Legion Go发布时间表已公布并列在该公司的官方网站上
- 苹果手表最佳优惠
- Stardock发布Fences5预览版现已适用于Windows11和10
- 揭晓Scout重新定义冒险骑行的终极步进电动自行车